
MapReduce is simple. Some MapReduce algorithms can definitely be more difficult to write than others, but MapReduce as a programming approach is easy. However, people usually struggle the first time they are exposed to it. In our opinion, this comes from the fact that most MapReduce tutorials focus on explaining how to build MapReduce algorithms. Unfortunately, the way MapReduce algorithms are built (i.e., by building a mapper and a reducer) is not necessarily the best way to explain how MapReduce works because it tends to overlook the ‘shuffle’ step, which occurs between the ‘map’ step and the ‘reduce’ step and is usually made transparent by MapReduce frameworks such as Hadoop.
This post is an attempt to present MapReduce the way we would have liked to be introduced to it from the start.
Before you start
This tutorial assumes a basic knowledge of the Python language.
You can download the code presented in the examples below from here. In order to run it, you need:
- A Unix-like shell (e.g., bash, tcsh) as provided on Linux, Mac OS X, or Windows + Cygwin;
- Python (e.g., anaconda), note that the examples presented here can be ported into any other language that permits to read data from the standard input and write it to the standard output.
In addition, if you want to run your code on Hadoop, you will need to install Hadoop 2.6, which requires java to run.
Counting Word Occurrences
Counting the number of occurrences of words in a text is sometimes considered as the “Hello world!” equivalent of MapReduce. A classical way to write such a program is presented in the python script below. The script is very simple. It parses the standard input from which it extracts and counts words and stores the result in a dictionary that uses words as keys and the number of occurrences as values.
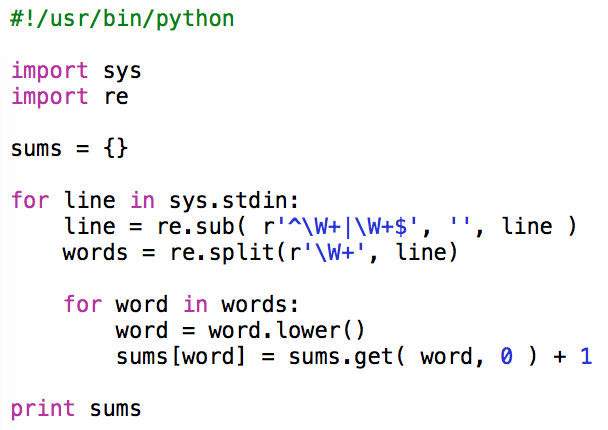
Let’s look at this script in more details. It uses 2 packages: ‘sys’, which allows for reading data from the standard input, and ‘re’, that provides support for regular expression.
import sys
import re
Before the parsing starts, a dictionary, named ‘sums’, which will be used to store the word counts, is created and initialized.
sums = {}
The standard input is read line by line and put in a variable named ‘line’
for line in sys.stdin:
For each line, a regular expression is used to remove all the leading and trailing non-word characters (e.g., blanks, tabs, punctuation)
line = re.sub( r'^\W+|\W+$', '', line )
Then a second regular expression is used to split the line (on non-word characters) into words. Note that removing the leading and trailing non-word characters before splitting the line on these non-word characters lets you avoid the creation of empty words. The words obtained this way are put in a list named ‘words’.
words = re.split( r'\W+', line )
Then, for each word in the list
for word in words:
The lower-case version of the word is taken.
word = word.lower()
Before the word is used as key to access the ‘sums’ dictionary and increment its value (i.e., the word occurrence count) by one. Note that taking the lower-case version of each word avoids counting the same word as different words when it appears with different combinations of upper- and lower-case characters in the parsed text.
sums[word] = sums.get( word, 0 ) + 1
Finally, once the whole text has been parsed, the content of the dictionary is sent to the standard output.
print sums
Now that the script is ready, let’s test it by counting the number of word occurrences in Moby Dick, the novel by Herman Melville. The text can be obtained here.
wget https://www.gutenberg.org/cache/epub/2701/pg2701.txt
mv pg2701.txt input.txt
Its content can be displayed using the cat command. As seen on the screenshot below, it finishes by a notice describing the Project Gutenberg.
cat input.txt

Assuming that the python script was saved in a file named counter.py, which was made executable (chmod +x counter.py), and that the text containing the words to count was saved in a file named input.txt, the script can be launched using the following command line:
./counter.py < input.txt
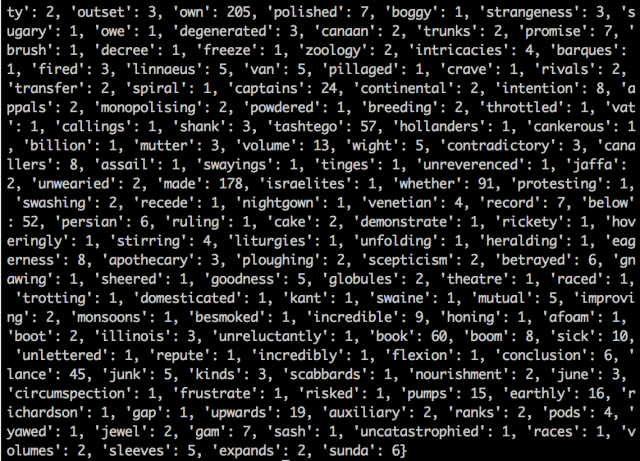
The result of this is partly displayed in the screenshot below where we can see that the word ‘own’ appears 205 times in the text, the word ‘polished’ appears 7 times, etc.
Limitations of the Dictionary Approach
The main problem with this approach comes from the fact that it requires the use of a dictionary, i.e., a central data structure used to progressively build and store all the intermediate results until the final result is reached.
Since the code we use can only run on a single processor, the best we can expect is that the time necessary to process a given text will be proportional to the size of the text (i.e., the number of words processed per second is constant). Actually, the performance degrades as the size of the dictionary grows. As shown on the diagram below, the number of words processed per second diminishes when the size of the dictionary reaches the size of the processor data cache (note that if the cache is structured in several layers of different speeds, the processing speed will decrease each time the dictionary reaches the size of a layer). A new diminution of the processing speed will be reached when the dictionary reaches the size of the Random Access Memory. Eventually, if the dictionary continues to grow, it will exceed the capacity of the swap and an exception will be raised.

The MapReduce Approach
The MapReduce approach does not require a central data structure. It consists of 3 steps:
- A mapping step that produces intermediate results and associates them with an output key;
- A shuffling step that groups intermediate results associated with the same output key; and
- A Reducing step that processes groups of intermediate results with the same output key.
This might seem a little abstract so let’s look at what these three steps look like in practice when applied to our example.
Mapping
The mapping step is very simple. It consists of parsing the input text, extracting the words it contains, and, for each word found, producing an intermediate result that says: “this word occurs one time”. Translated into an output key / intermediate result format, this is expressed by using the word itself as output key and the number of occurrences of the word (in this specific case ‘1’) as intermediate result.
The code of the mapper is provided below:

The beginning of the script is identical to the initial script. The standard input is read line by line and split into words.
Then, for each word in the list
for word in words:
The lower-case version of the word is sent to the standard output followed by a tabulation and the number 1.
print( word.lower() + "\t1" )
The word is used as output key and “1” (i.e., the number of occurrences of this word) is the intermediate value. Following a Hadoop convention, the tabulation character (“\t”) is used to separate the key from the value.
As in the initial script, taking the lower-case version of each word avoids counting the same word as different words when it appears with different combination of upper- and lower-case characters in the parsed text.
Assuming that the mapping script is saved in a file named mapper.py, the script can be launched using the following command line:
./mapper.py < input.txt
The result of this is partly displayed in the screenshot below where we can see that the words are sent in the order they appear in text, each of them followed by a tabulation and the number 1.

Shuffling
The shuffling step consists of grouping all the intermediate values that have the same output key. As in our example, the mapping script is running on a single machine using a single processor and the shuffling simply consists of sorting the output of the mapping. This can easily be achieved using the standard “sort” command provided by the operating system:
./mapper.py < input.txt | sort
The result of this is partly displayed in the screenshot below. It differs from the output of mapper.py by the fact that the keys (i.e., the words) are now sorted in alphabetic order.

Reducing
Now that the different values are ordered by keys (i.e., the different words are listed in alphabetic order), it becomes easy to count the number of times they occur by summing values as long as they have the same key and publish the result once the key changes.

Let’s look at the reducing script in more details. Like the other scripts, it uses the package ‘sys’, which allows for reading data from the standard input.
import sys
Before the parsing of the standard input starts, two variables are created: ‘sum’, which will be used to store the count of the current word and is initialized to 0 and ‘previous’ that will be used to store the previous key and is initialized to None.
previous = None
sum = 0
Then the standard input is read line by line and put in a variable named ‘line’
for line in sys.stdin:
Then, the key and value are extracted of each line by splitting the line on the tab character.
key, value = line.split( '\t' )
The current key (key) is compared to the previous one (previous).
if key != previous:
If the current and previous key are different, it means that a new word has be found and, unless the previous key is empty, this is not the first word (i.e., the script is not handling the very first line of the standard input)
if previous is not None:
The variable ‘count’ contains the total number of occurrences of the previous word and this result can be displayed (note that this result is also produced using the key-tabulation-value format).
print str( sum ) + '\t' + previous
As a new word is found, it is necessary to reinitiate the working variables
previous = key
sum = 0
And, in all cases, the loop ends with adding the current ‘value’ to the ‘sum’
sum = sum + int( value )
Finally, after having exited the loop, the last result can be displayed
print str( sum ) + '\t' + previous
Assuming that the reducing script is saved in a file named reducer.py, the full MapReduce job can be launched using the following command line:
./mapper.py < input.txt | sort | ./reducer.py
The result of this is partly displayed in the screenshot below where we can see one word per line with each word preceded by the number of times it occurs in the text.

MapReduce Frameworks
In the example above, which runs on a single processing unit, Unix pipes and the sort command are used to group the mapper’s output by key so that it can be consumed by the reducer.
./mapper.py < input.txt | sort | ./reducer.py
Similarly, when using a cluster of computers, a MapReduce framework such as Hadoop is responsible for redistributing data (produced in parallel by mappers running on the different cluster nodes using local data) so that all data with the same output key ends up on the same node to be consumed by a reducer.
As shown by the bash code below, the mapper.py and reducer.py scripts presented above do not need to be changed in order to run on Hadoop.

Note that:
- The output will appear in a file automatically created in directory ‘./output’ (Hadoop will fail if this directory is not empty);
- Environment variable HADOOP_HOME must point to the directory in which Hadoop has been uncompressed.
Hopefully, as you see, this tutorial simplifies your introduction to MapReduce by making explicit the shuffle step. If you know other ways to learn MapReduce we will be interested to hear about it.

Reblogged this on indigotech007 and commented:
Programming
LikeLike
Reblogged this on SutoCom Solutions.
LikeLike
Thank you very much indeed!
LikeLike
Pingback: برنامه نویسی نگاشت-کاهش با پایتون – پردازش کلان داده ها و سیستم های توزیع شده